哈囉大家好,我是橘白卯咪,歡迎大家來看看我能不能撐過30天
從第12天到現在,我們努力的從資料集開始建立,到現在模型已經訓練好,接著就是來測試了
如果使用第11天所介紹的工具,會得到影片與文字檔案兩種結果
今天要來介紹最容易了解的一種:影片
當你餵給系統一部測試影片,花了許多時間,他成功跑出結果的畫面會長這樣子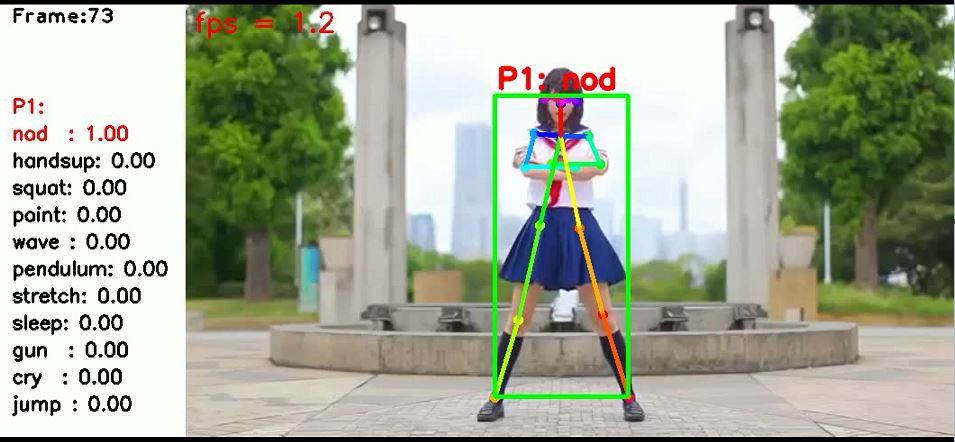
你可以看到目前的幀數、逐幀判斷的結果、關鍵點抓取的狀況跟實際影片的畫面
這時候可以做一個很有趣的嘗試
一個準確度99%模型,行為辨識的結果真的對了整個影片的99%嗎?
這是一個蠻難想像的狀況,準確度報告明明就跟你掛保證了
在過往行為辨別這件事,都是靠著人力,一分一秒仔細的看過給結論
但是人不是十全十美的,每個人可能會累、會有個人觀點、會改變想法
所以可能前面覺得頭有點小小低就是在打瞌睡了,後面才發現原來這個人低頭是在划手機...
兩個人坐在同一個地點,看同一個影片可能都有不同想法了
於是在質性研究當中,會對兩個人的觀察結果做評分者間信度
今天我們既然訓練出一個會辨識行為的模型,也會好奇它跟真實的人類比起來,辨識的結果是否有差異吧?
所以可以將系統比對出的結果,當作某一位不知名的觀察者的結果
做成這樣的一張表
| 幀別 | 人 | 機器 |
|---|---|---|
| 1 | dab | dab |
| 2 | dab | other |
| 3 | dab | dab |
| 4 | other | dab |
| ... | ... | ... |
| 99 | dab | other |
然後算算兩者之間的一致性 附上工具
究竟準確度99%的模型,是否也是個99%準確度的觀察者呢?
附上某一次我訓練的,準確度83%模型跑出來的影片判讀結果,以及人工再判斷一次結果的比較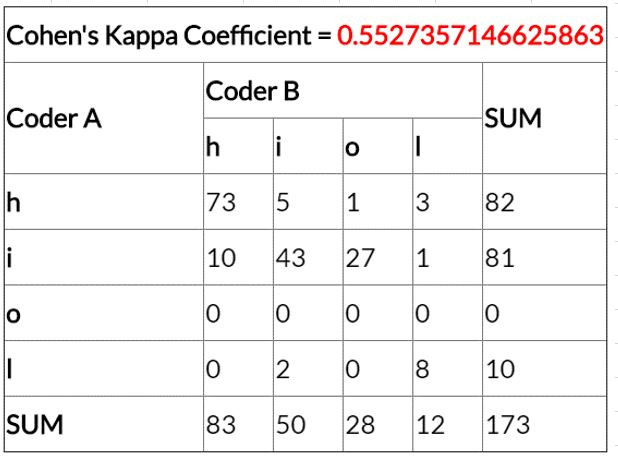
一致性竟然只有一般般
到底發生了什麼事呢??
有可能是該次的訓練資料,在人工標記的時候有所偏差,導致模型也產生了偏差
或是跟判斷的方法有關,根據單幀影像判斷的方法缺少前後文判斷
大家測試的結果如何呢?
如果你一秒鐘幾百萬上下,實在沒有時間看完整個結果影片的話
明天,讓我們來想想,不用看完影片也可以了解辨識結果的方法~


 iThome鐵人賽
iThome鐵人賽